Inhalt
Fortsetzung von Teil 1
Massen User Test für Power BI – Warum und Wie erfährst Du in Teil 1…
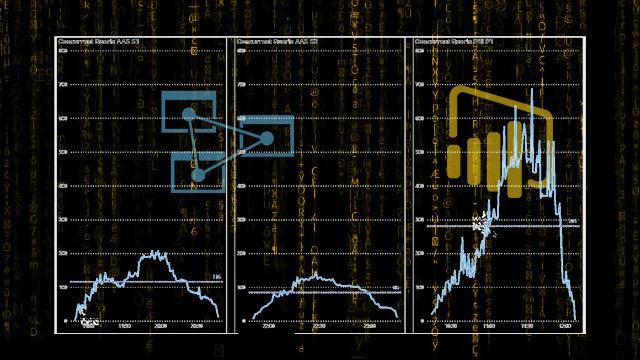
Vergleich AAS vs. PBI
Bei dem Test wollte ich auch Grundlagen schaffen, ob ein AAS (Azure Analysis Services) im Vorteil gegenüber Power BI Premium ist, denn ich bin hier voreingenommen, es ist zwar die selbe Technologie, aber Power BI ist mehr oder weniger eine “Black Box” und instiktiv habe ich gerne alle Backend-Services “unter einem Dach” in Azure unter Kontrolle und gut monitored und nur das Reporting in Power BI.
Daher laufen alle Test auf einem identisches Modell und auch gleicher Skalierung jeweils gegen AAS S1 und Premium P1.

Ergebnisse
Super, der Massentest läuft – mit ADF und SSIS, einer starken IR und sogar im Vollausbau bis 750 gleichzeitigen Prozessen (DAX-Queries), gegen Azure Analysis Services und gegen Power BI Premium Dataset.
Jetzt brauche ich nur mehr die Ergebnisse analysieren…
Aber wie?

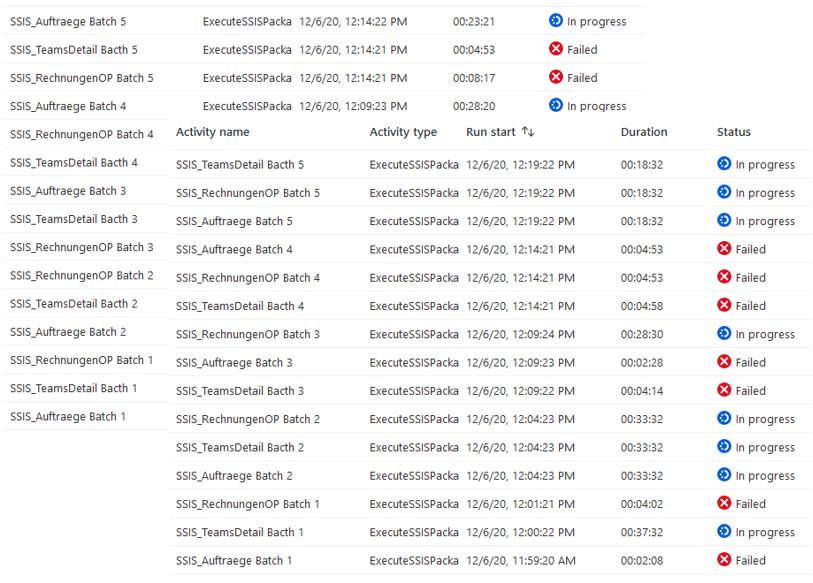
 SSIS Logs
SSIS Logs
Es wird von SSIS einiges geloggt, das landet in der SSISDB oder im Filesystem, dort kann man es etwas umständlich aber doch mit SQL auswerten.
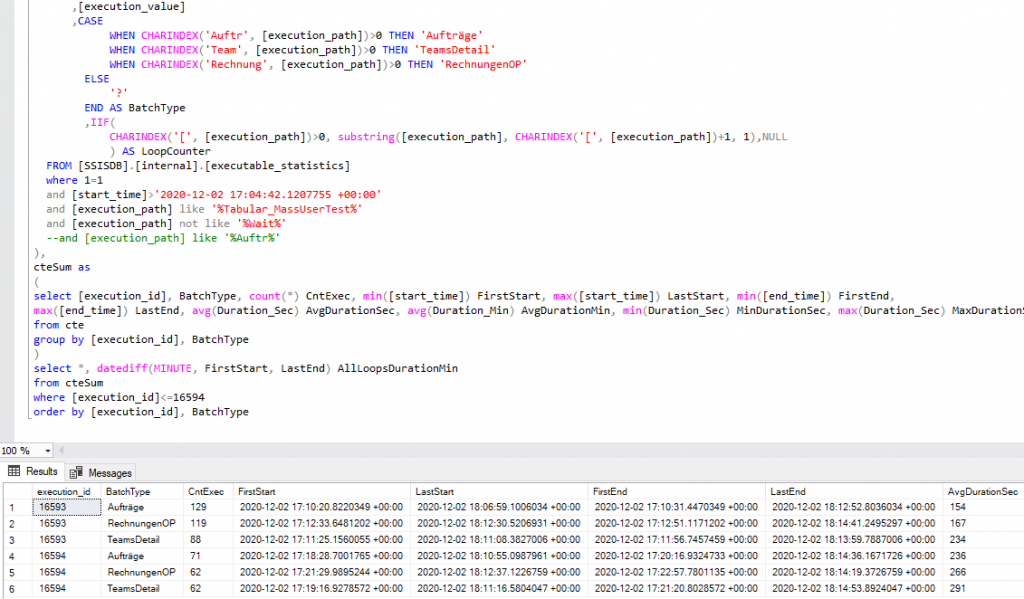
Aber, ab einem bestimmten Zeitpunkt kam hier nichts mehr an, das Logging-System war überlastet oder Deadlocks – ist wohl auch nicht so gedacht, dass 750 Prozesse laufen.
Ohne vollständige Logs keine Ergebnisse!
ADF Diagnostic
Also habe ich es anders versucht, mit den Diagnostics der Azure Data Factory.
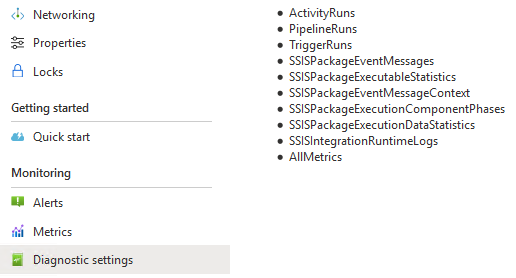
Diese Logs sind im wesentlichen die gleichen SSIS-Logs und noch zusätzlich jene der ADF, und es ist offensichtlich kein Problem alle Prozessse parallel auf einen Datalake zu streamen.

Die Logs sind in “hunderte” Unterordner partitioniert, wie das am Data lake bei vielen Files und parallelen Prozessen so üblich ist.
Aber auch das ist ja kein Problem, denn mit Power BI kann man bequem einen ganzen Ordner rekursiv einlesen und auch JSON kann Power BI ja auflösen – und dann kann die Auswertung beginnen…
Leider nicht. Power BI verweigert!
ADF Diagnostic Logs
Will man die Files nun alle einlesen hat man leider Pech, denn das Log ist ein ungültiges JSON! (Das diskutiere ich bereits seit Monaten mit Microsoft).
Es ist ein Line-JSON was als ganzes keine gültige Struktur hat, also habe ich die Files manuell zusammenkopiert, denn ich wollte jetzt endlich(!!!) die Ergebnisse sehen.
Wer übrigens mit großen Files arbeitet und da drinnen auch noch “Suchen&Ersetzen” machen will, der ist mit Notepad++ oder ähnlichem schnell am Limit – ich empfehle: EmEditor – impressiv!
Nach dem Import und etwas gebastel in PowerQuery können die Daten analysiert werden.
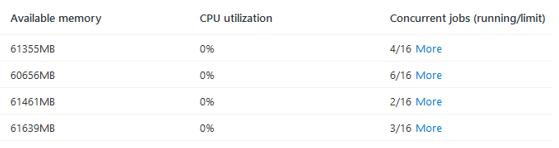
Azure Datafactory Log
Auch das Log der ADF gibt einigen Aufschluß, welcher Prozess lief und welcher schief ging, wie belastet die IR ist, etc.
ERGEBNIS
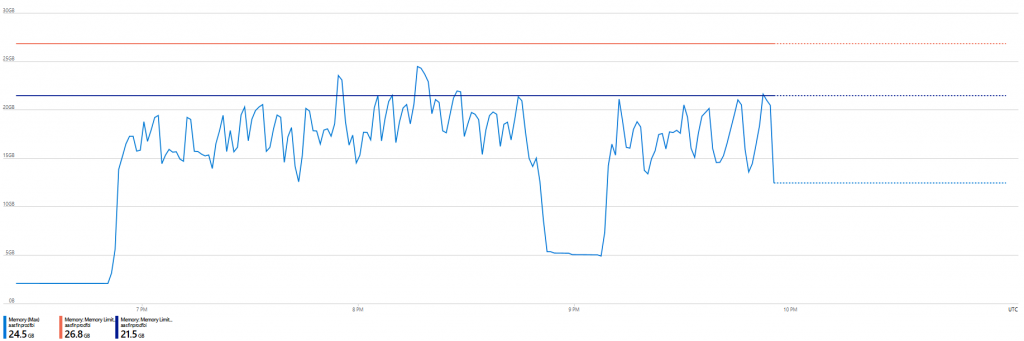
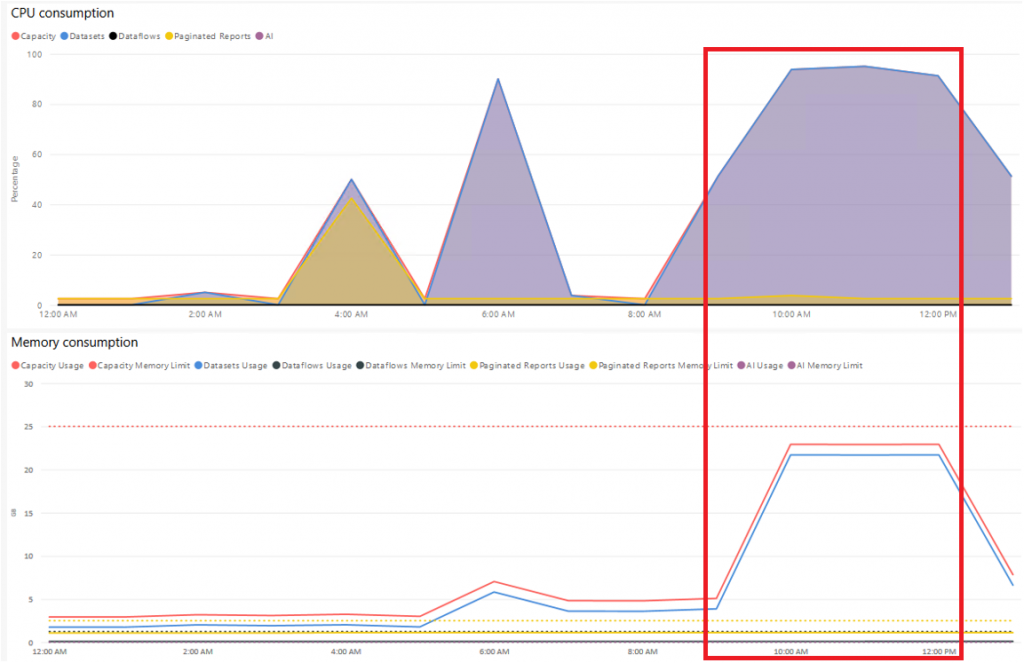
Azure Analysis Services (AAS S1) läuft sehr stabil, praktisch keine Ausfälle, hat aber einen deutlich geringeren Durchsatz.
Die Speicherauslastung ist gleichmäßig hoch, mit steigender Anzahl der Prozesse bleibt alles in Betrieb.
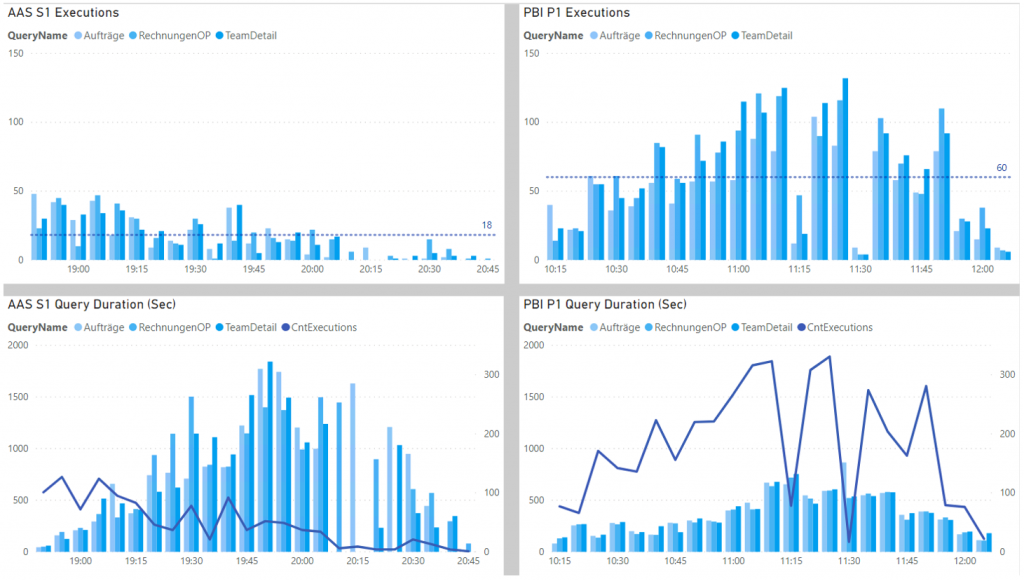
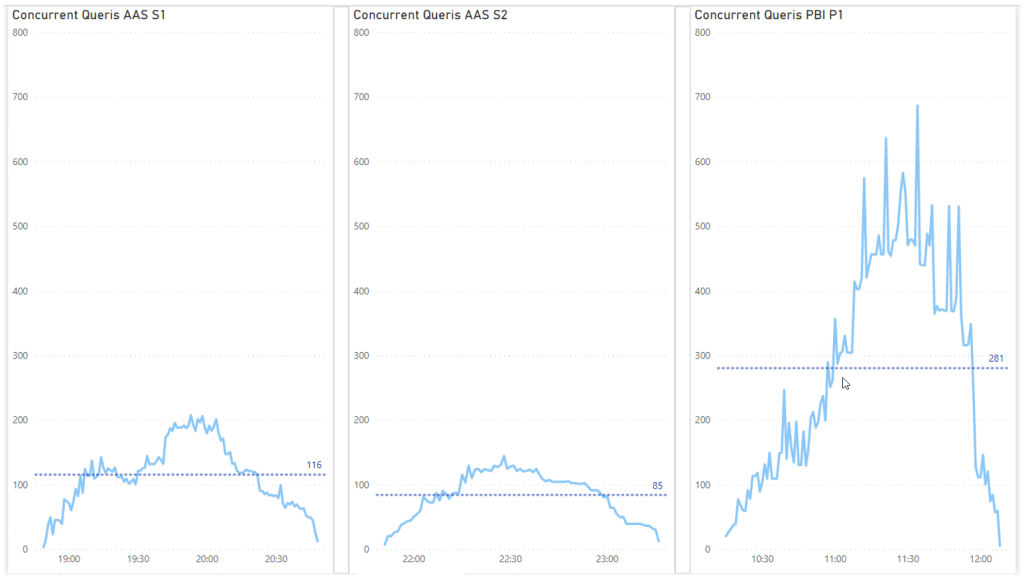
AAS schafft es auf 200 gleichzeitige Abfragen, durschnittlich 120 (pro 5 Min.).
Power BI Premium (P1) hat einige Ausfälle einzelner Queries, braucht auch recht lange bis er sich wieder “beruhigt” vom Max. Memory Usage, hat aber einen sehr hohen Durchsatz.
Die Speicherauslastung und CPU geht rasch nach oben und bleibt am Limit, neue Queries werden abgelehnt.
PBI kommt auf bis zu 500 Abfragen, manchmal auch mehr, durschnittlich 280 (pro 5 Min.).
AAS S2
Irgendwie wollte ich es nicht wahr haben, dass der AAS so schlecht abgeschnitten hatte und so habe den Test mit S2 wiederholt, das Ergebnis war noch schlechter.
Das sind natürlich nur Momentaufnahmen und es spielen viele Faktoren mit, wie Regionen der Services, Azure Schwankungen, zugeteilte Resourcen, etc.
ERGEBNIS Grafiken
AAS Scale Out
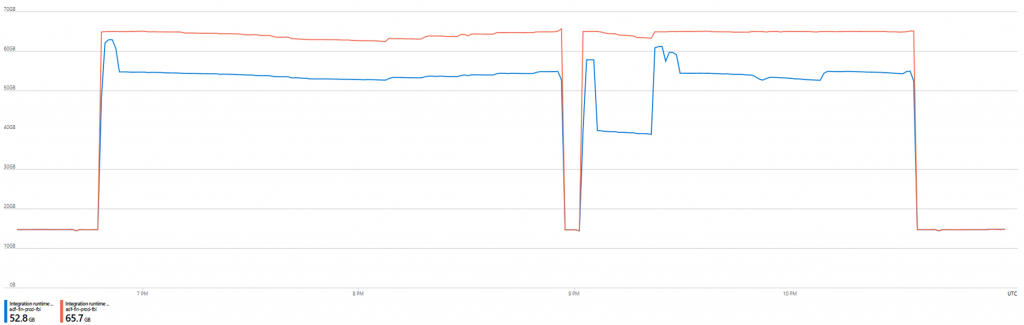
Ich wollte es immer noch nicht wahr haben und habe am AAS noch getunt, denn der Test war ja schon fertig und musste nur mehr mit einem Klick gestartet werden.
Zunächst habe ich die Query-Prioritäen umgestellt, so dass kürzere Queries auch in der Mitte drinnen von Langläufern Resourcen bekommen.
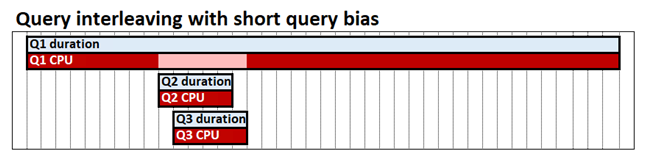
Es wird zwar sehr schnell der volle Memory benütze, aber irgendwann hilft das kaum weiter, daher auch beim S2 kaum Verbesserung, es muss also an der Compute-Power liegen mehr gleichzeitig zu verarbeiten, daher habe ich ein Scale Out gemacht.
Man sieht sofort, dass die maximal möglichen 100 QPU mit dem Scale Out verdoppelt werden und auch der Memory genützt wird von der Replica.
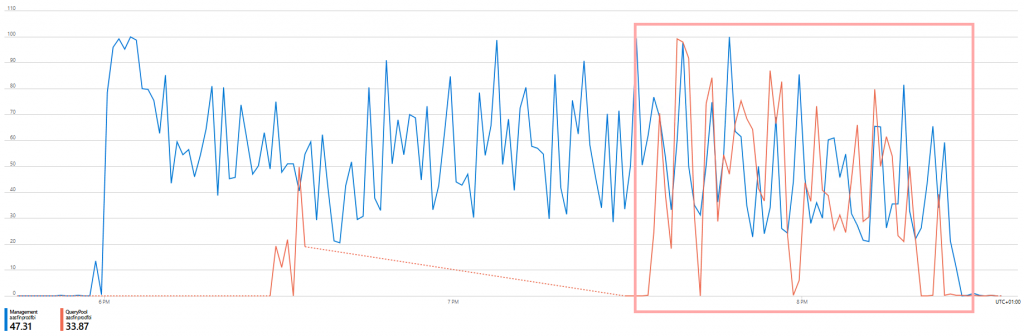
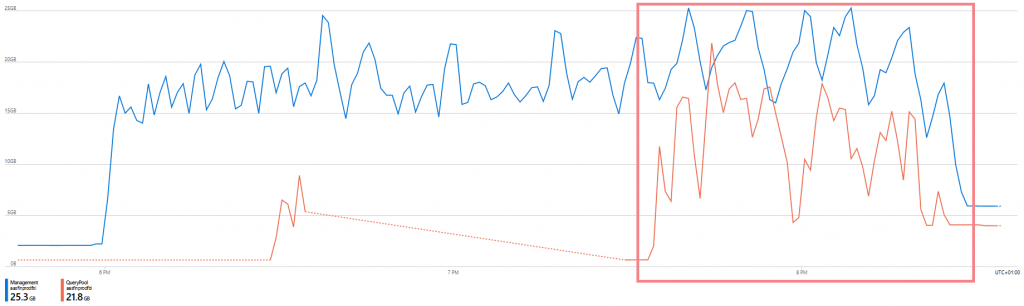
Und siehe da, sofort kommt der Durchsatz deutlich in die Nähe von Power BI Premium.
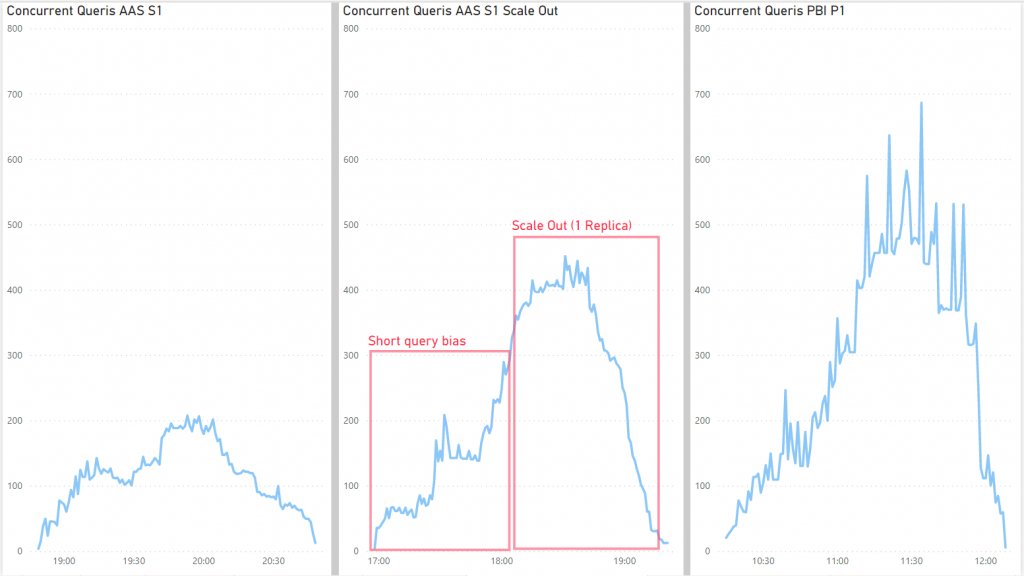
30 Minuten unter Volllast sind die gleichzeitigen Queries fast gleich.
Die Performance ist bei PBI aber immer noch besser.
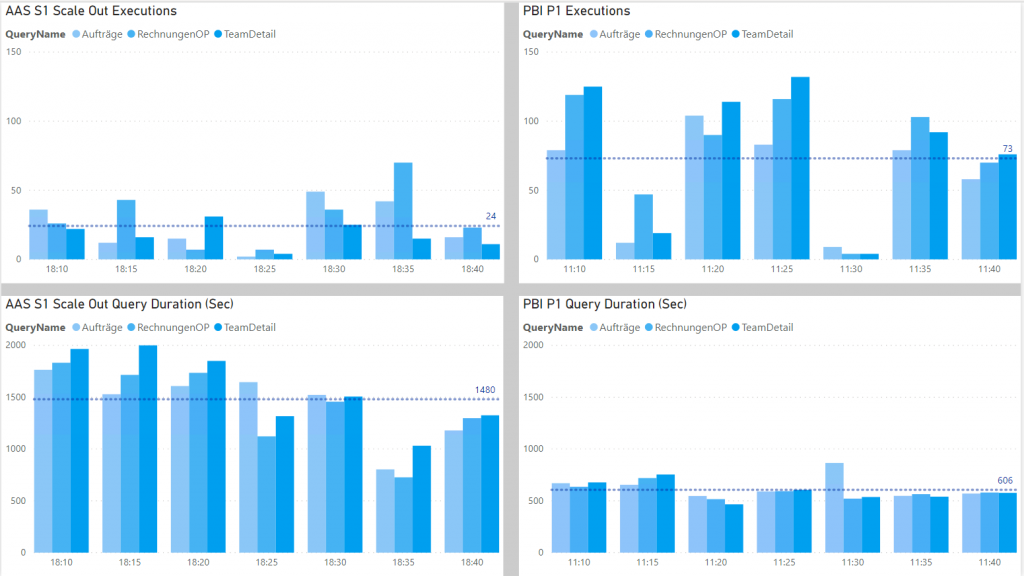
Conclusio
Power BI Premium kann das relativ kleine aber komplexe Modell auch bei vielen Zugriffen noch bedienen, einige Queries kommen nicht mehr zum Enduser, wenn das System auf Anschlag ist, aber der Großteil hat einen guten Durchsatz und Reaktionszeit.
500 User sollte das System gut verkraften, bei den geplanten 1.000 oder mehr wird es spannend…
Der AAS ist diesem Zusamenhang eher keine Alternative, zumindest in der vergleichbaren Variante.
Eine enorme Steigerung ergibt sich aber durch ein Scale Out.
Power BI ist deutlich besser, der Hauptvorteil an AAS ist die einfache Skalierbarkeit und zwar jederzeit, je nach Bedarf – wird es eng zum Monatsabschluß, so schaltet man 1-2 Replicas für ein paar Stunden dazu und am Wochenende ganz ab um Geld zu sparen.
Vielleicht mache ich noch einen 3. Teil, wenn dann tatsächlich die 1.000 User starten – hoffentlich nicht mit dem Titel “Dream and Reality”…
Schreibe einen Kommentar